Gradient-based matching of parameters against observations
Immiscible HistoryMatching Differentiability IntroductionWe create a simple test problem: A 1D nonlinear displacement. The observations are generated by solving the same problem with the true parameters. We then match the parameters against the observations using a different starting guess for the parameters, but otherwise the same physical description of the system.
This example uses the numerical parameter optimization framework in Jutul for model calibration. Later on, the high-level interface for optimization is also demonstrated.
using Jutul
using JutulDarcy
using LinearAlgebra
using GLMakieDefine a setup function
irate = 10.0
function setup_bl(;nc = 100, time = 1.0, nstep = 100, poro = 0.1, perm = 0.1*si_unit(:darcy))
T = time
tstep = repeat([T/nstep], nstep)
G = get_1d_reservoir(nc, poro = poro, perm = perm)
nc = number_of_cells(G)
bar = 1e5
p0 = 1000*bar
sys = ImmiscibleSystem((LiquidPhase(), VaporPhase()))
model = SimulationModel(G, sys)
model.primary_variables[:Pressure] = Pressure(minimum = -Inf, max_rel = nothing)
kr = BrooksCoreyRelativePermeabilities(sys, [2.0, 2.0])
replace_variables!(model, RelativePermeabilities = kr)
tot_time = sum(tstep)
parameters = setup_parameters(model, PhaseViscosities = [1e-3, 5e-3]) # 1 and 5 cP
state0 = setup_state(model, Pressure = p0, Saturations = [0.0, 1.0])
src = [SourceTerm(1, irate, fractional_flow = [1.0-1e-3, 1e-3]),
SourceTerm(nc, -irate, fractional_flow = [1.0, 0.0])]
forces = setup_forces(model, sources = src)
return JutulCase(model, tstep, forces, state0 = state0, parameters = parameters)
endsetup_bl (generic function with 1 method)Number of cells and time-steps
N = 100
Nt = 100
poro_ref = 0.1
perm_ref = 0.1*si_unit(:darcy)9.86923266716013e-14Set up and simulate reference
case_ref = setup_bl(nc = N, nstep = Nt, poro = poro_ref, perm = perm_ref)
states_ref, = simulate(case_ref);Jutul: Simulating 1 second as 100 report steps
╭────────────────┬───────────┬───────────────┬──────────╮
│ Iteration type │ Avg/step │ Avg/ministep │ Total │
│ │ 100 steps │ 100 ministeps │ (wasted) │
├────────────────┼───────────┼───────────────┼──────────┤
│ Newton │ 3.01 │ 3.01 │ 301 (0) │
│ Linearization │ 4.01 │ 4.01 │ 401 (0) │
│ Linear solver │ 3.01 │ 3.01 │ 301 (0) │
│ Precond apply │ 0.0 │ 0.0 │ 0 (0) │
╰────────────────┴───────────┴───────────────┴──────────╯
╭───────────────┬─────────┬────────────┬────────╮
│ Timing type │ Each │ Relative │ Total │
│ │ ms │ Percentage │ s │
├───────────────┼─────────┼────────────┼────────┤
│ Properties │ 0.0150 │ 0.08 % │ 0.0045 │
│ Equations │ 1.3967 │ 9.44 % │ 0.5601 │
│ Assembly │ 0.9014 │ 6.09 % │ 0.3615 │
│ Linear solve │ 7.7192 │ 39.17 % │ 2.3235 │
│ Linear setup │ 0.0000 │ 0.00 % │ 0.0000 │
│ Precond apply │ 0.0000 │ 0.00 % │ 0.0000 │
│ Update │ 1.2121 │ 6.15 % │ 0.3648 │
│ Convergence │ 1.7046 │ 11.52 % │ 0.6835 │
│ Input/Output │ 0.4493 │ 0.76 % │ 0.0449 │
│ Other │ 5.2803 │ 26.79 % │ 1.5894 │
├───────────────┼─────────┼────────────┼────────┤
│ Total │ 19.7084 │ 100.00 % │ 5.9322 │
╰───────────────┴─────────┴────────────┴────────╯Set up another case where the porosity is different
case_dporo = setup_bl(nc = N, nstep = Nt, poro = 2*poro_ref, perm = 1.0*perm_ref)
states, rep = simulate(case_dporo);Jutul: Simulating 1 second as 100 report steps
╭────────────────┬───────────┬───────────────┬──────────╮
│ Iteration type │ Avg/step │ Avg/ministep │ Total │
│ │ 100 steps │ 100 ministeps │ (wasted) │
├────────────────┼───────────┼───────────────┼──────────┤
│ Newton │ 3.0 │ 3.0 │ 300 (0) │
│ Linearization │ 4.0 │ 4.0 │ 400 (0) │
│ Linear solver │ 3.0 │ 3.0 │ 300 (0) │
│ Precond apply │ 0.0 │ 0.0 │ 0 (0) │
╰────────────────┴───────────┴───────────────┴──────────╯
╭───────────────┬────────┬────────────┬──────────╮
│ Timing type │ Each │ Relative │ Total │
│ │ ms │ Percentage │ ms │
├───────────────┼────────┼────────────┼──────────┤
│ Properties │ 0.0143 │ 1.34 % │ 4.2872 │
│ Equations │ 0.0166 │ 2.07 % │ 6.6510 │
│ Assembly │ 0.0082 │ 1.02 % │ 3.2747 │
│ Linear solve │ 0.9535 │ 89.20 % │ 286.0623 │
│ Linear setup │ 0.0000 │ 0.00 % │ 0.0000 │
│ Precond apply │ 0.0000 │ 0.00 % │ 0.0000 │
│ Update │ 0.0136 │ 1.28 % │ 4.0902 │
│ Convergence │ 0.0189 │ 2.35 % │ 7.5414 │
│ Input/Output │ 0.0151 │ 0.47 % │ 1.5121 │
│ Other │ 0.0242 │ 2.27 % │ 7.2690 │
├───────────────┼────────┼────────────┼──────────┤
│ Total │ 1.0690 │ 100.00 % │ 320.6878 │
╰───────────────┴────────┴────────────┴──────────╯Plot the results
fig = Figure()
ax = Axis(fig[1, 1], title = "Saturation")
lines!(ax, states_ref[end][:Saturations][1, :], label = "Reference")
lines!(ax, states[end][:Saturations][1, :], label = "Initial guess")
axislegend(ax)
ax = Axis(fig[1, 2], title = "Pressure")
lines!(ax, states_ref[end][:Pressure], label = "Reference")
lines!(ax, states[end][:Pressure], label = "Initial guess")
axislegend(ax)
fig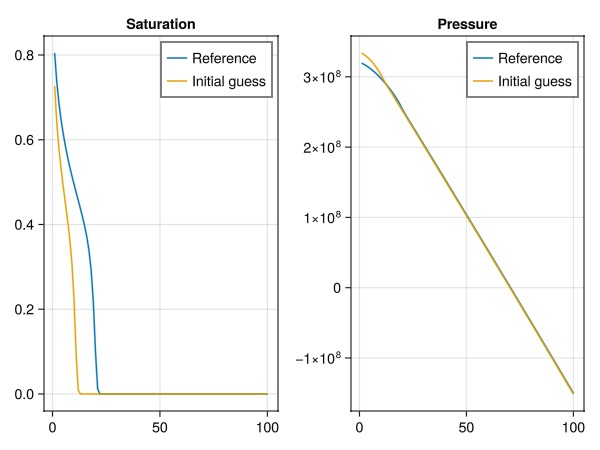
Define objective function
Define objective as mismatch between water saturation in current state and reference state. The objective function is currently a sum over all time steps. We implement a function for one term of this sum.
step_times = cumsum(case_ref.dt)
function saturation_mismatch(m, state, dt, step_info, forces)
t = step_info[:time]
step_no = findmin(x -> abs(x - t), step_times)[2]
state_ref = states_ref[step_no]
fld = :Saturations
val = state[fld]
ref = state_ref[fld]
err = 0
for i in axes(val, 2)
err += (val[1, i] - ref[1, i])^2
end
return dt*err
end
forces = case_ref.forces
dt = case_ref.dt
model = case_ref.model
@assert Jutul.evaluate_objective(saturation_mismatch, model, states_ref, dt, forces) == 0.0
@assert Jutul.evaluate_objective(saturation_mismatch, model, states, dt, forces) > 0.0Set up a configuration for the optimization
The optimization code enables all parameters for optimization by default, with relative box limits 0.1 and 10 specified here. If use_scaling is enabled the variables in the optimization are scaled so that their actual limits are approximately box limits.
We are not interested in matching gravity effects or viscosity here. Transmissibilities are derived from permeability and varies significantly. We can set log scaling to get a better conditioned optimization system, without changing the limits or the result.
cfg = optimization_config(case_dporo, use_scaling = true, rel_min = 0.1, rel_max = 10)
for (ki, vi) in cfg
if ki in [:TwoPointGravityDifference, :PhaseViscosities, :Transmissibilities]
vi[:active] = false
end
end
print_obj = 100;Set up parameter optimization
This gives us a set of function handles together with initial guess and limits. Generally calling either of the functions will mutate the data Dict. The options are: F_o(x) -> evaluate objective dF_o(dFdx, x) -> evaluate gradient of objective, mutating dFdx (may trigger evaluation of F_o) F_and_dF(F, dFdx, x) -> evaluate F and/or dF. Value of nothing will mean that the corresponding entry is skipped.
F_o, dF_o, F_and_dF, x0, lims, data = setup_parameter_optimization(case_dporo, saturation_mismatch, cfg, print = print_obj, param_obj = true);
F_initial = F_o(x0)
dF_initial = dF_o(similar(x0), x0)
@info "Initial objective: $F_initial, gradient norm $(norm(dF_initial))"Parameters for model
┌─────────────┬────────┬─────┬─────────┬─────────────────┬─────────────┬────────
│ Name │ Entity │ N │ Scale │ Abs. limits │ Rel. limits │ ⋯
├─────────────┼────────┼─────┼─────────┼─────────────────┼─────────────┼────────
│ FluidVolume │ Cells │ 100 │ default │ [2.22e-16, Inf] │ [0.1, 10] │ [0.00 ⋯
└─────────────┴────────┴─────┴─────────┴─────────────────┴─────────────┴────────
3 columns omitted
[ Info: Initial objective: 0.6761923949345445, gradient norm 4.126710434487178Link to an optimizer package
We use Optim.jl but the interface is general enough that e.g. LBFGSB.jl can easily be swapped in.
LBFGS is a good choice for this problem, as Jutul provides sensitivities via adjoints that are inexpensive to compute.
import Optim
lower, upper = lims
inner_optimizer = Optim.LBFGS()
opts = Optim.Options(store_trace = true, show_trace = true, time_limit = 30, f_abstol = 0.01)
results = Optim.optimize(F_o, dF_o, lower, upper, x0, Optim.Fminbox(inner_optimizer), opts)
x = results.minimizer
display(results)
F_final = F_o(x)0.0015412125482875119Compute the solution using the tuned parameters found in x.
parameters_t = deepcopy(case_dporo.parameters)
devectorize_variables!(parameters_t, model, x, data[:mapper], config = data[:config])
x_truth = vectorize_variables(case_ref.model, case_ref.parameters, data[:mapper], config = data[:config])
states_tuned, = simulate(case_dporo.state0, case_dporo.model, case_dporo.dt, parameters = parameters_t, forces = case_dporo.forces);Jutul: Simulating 1 second as 100 report steps
╭────────────────┬───────────┬───────────────┬──────────╮
│ Iteration type │ Avg/step │ Avg/ministep │ Total │
│ │ 100 steps │ 100 ministeps │ (wasted) │
├────────────────┼───────────┼───────────────┼──────────┤
│ Newton │ 3.01 │ 3.01 │ 301 (0) │
│ Linearization │ 4.01 │ 4.01 │ 401 (0) │
│ Linear solver │ 3.01 │ 3.01 │ 301 (0) │
│ Precond apply │ 0.0 │ 0.0 │ 0 (0) │
╰────────────────┴───────────┴───────────────┴──────────╯
╭───────────────┬──────────┬────────────┬──────────╮
│ Timing type │ Each │ Relative │ Total │
│ │ μs │ Percentage │ ms │
├───────────────┼──────────┼────────────┼──────────┤
│ Properties │ 13.6978 │ 3.01 % │ 4.1230 │
│ Equations │ 15.9293 │ 4.67 % │ 6.3877 │
│ Assembly │ 7.8945 │ 2.31 % │ 3.1657 │
│ Linear solve │ 344.9630 │ 75.88 % │ 103.8339 │
│ Linear setup │ 0.0000 │ 0.00 % │ 0.0000 │
│ Precond apply │ 0.0000 │ 0.00 % │ 0.0000 │
│ Update │ 12.8490 │ 2.83 % │ 3.8675 │
│ Convergence │ 18.2582 │ 5.35 % │ 7.3215 │
│ Input/Output │ 13.4847 │ 0.99 % │ 1.3485 │
│ Other │ 22.5717 │ 4.96 % │ 6.7941 │
├───────────────┼──────────┼────────────┼──────────┤
│ Total │ 454.6242 │ 100.00 % │ 136.8419 │
╰───────────────┴──────────┴────────────┴──────────╯Plot final parameter spread
println("Final residual $F_final (down from $F_initial)")
fig = Figure()
ax1 = Axis(fig[1, 1], title = "Scaled parameters", ylabel = "Value")
scatter!(ax1, x, label = "Final X")
scatter!(ax1, x0, label = "Initial X")
scatter!(ax1, x_truth, label = "Reference X")
lines!(ax1, lower, label = "Lower bound")
lines!(ax1, upper, label = "Upper bound")
axislegend()
fig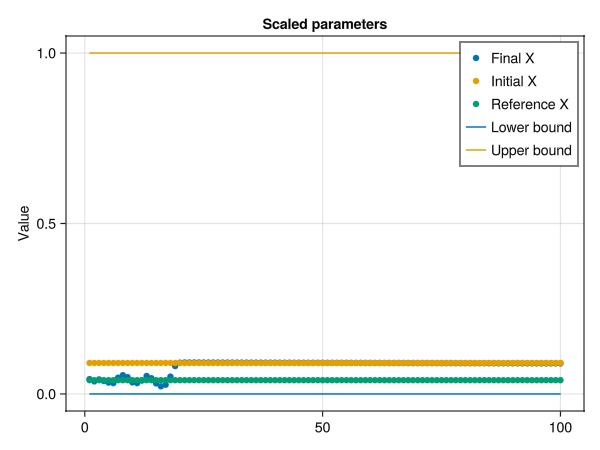
Plot the final solutions.
Note that we only match saturations - so any match in pressure is not guaranteed.
fig = Figure()
ax = Axis(fig[1, 1], title = "Saturation")
lines!(ax, states_ref[end][:Saturations][1, :], label = "Reference")
lines!(ax, states[end][:Saturations][1, :], label = "Initial guess")
lines!(ax, states_tuned[end][:Saturations][1, :], label = "Tuned")
axislegend(ax)
ax = Axis(fig[1, 2], title = "Pressure")
lines!(ax, states_ref[end][:Pressure], label = "Reference")
lines!(ax, states[end][:Pressure], label = "Initial guess")
lines!(ax, states_tuned[end][:Pressure], label = "Tuned")
axislegend(ax)
fig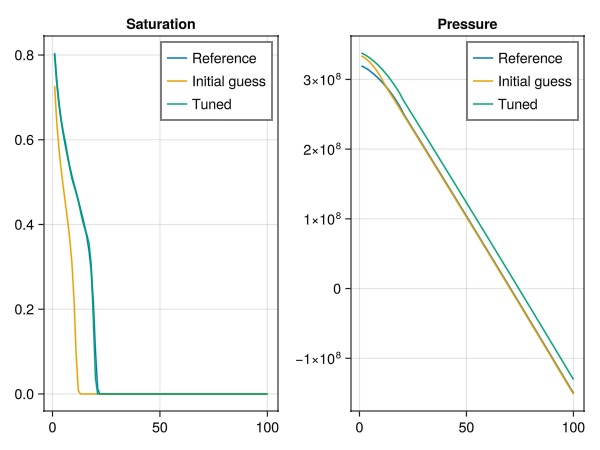
Plot the objective history and function evaluations
fig = Figure()
ax1 = Axis(fig[1, 1], yscale = log10, title = "Objective evaluations", xlabel = "Iterations", ylabel = "Objective")
plot!(ax1, data[:obj_hist][2:end])
ax2 = Axis(fig[1, 2], yscale = log10, title = "Outer optimizer", xlabel = "Iterations", ylabel = "Objective")
t = map(x -> x.value, Optim.trace(results))
plot!(ax2, t)
fig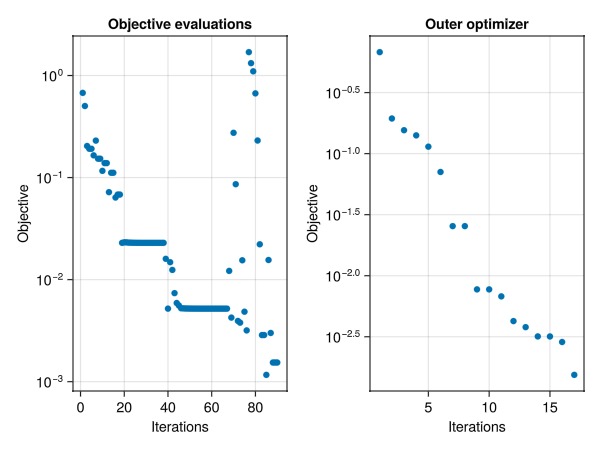
Define an alternative optimization
We can also use the generic interface for optimization, which is a bit less efficient in terms of evaluating the gradients, but a lot more flexible. The previous optimization interface works on numerical parameters (like pore-volumes, transmissibilities, etc.), while the generic interface allows for both numerical and input parameters (like permeability, porosity, etc.).
Note that the viscosity is not defaulted - so we need to let the solver know that it needs to treat it as a distinct parameter, even if we do not optimize on it directly. This calls the builtin Jutul optimizer, which generally attempts to minimize the number of objective evaluations due to the cost of performing a simulation. This is generally advantageous for history matching problems, where the cost of evaluating the objective is high relative to the cost of the work done by the optimizer itself.
opt = setup_reservoir_dict_optimization(case_dporo, parameters = [:PhaseViscosities])
free_optimization_parameter!(opt, [:model, :porosity], rel_min = 0.1, rel_max = 10.0)
prm_opt = optimize_reservoir(opt, saturation_mismatch);
optDictParameters with 6 parameters (1 active), and 0 multipliers:
Active optimization parameters
┌────────────────┬───────────────┬───────┬──────┬─────┬─────────────────┬───────
│ Name │ Initial value │ Count │ Min │ Max │ Optimized value │ Chan ⋯
├────────────────┼───────────────┼───────┼──────┼─────┼─────────────────┼───────
│ model.porosity │ 0.2 ± 0.0 │ 100 │ 0.02 │ 2.0 │ 0.181 ± 0.103 │ -9. ⋯
└────────────────┴───────────────┴───────┴──────┴─────┴─────────────────┴───────
1 column omitted
Inactive optimization parameters
┌─────────────────────────────┬───────────────────────────────────┬───────┬─────
│ Name │ Initial value │ Count │ Mi ⋯
├─────────────────────────────┼───────────────────────────────────┼───────┼─────
│ model.permeability │ 9.87e-14 ± 1.2600000000000001e-29 │ 100 │ ⋯
│ model.rock_density │ 2000.0 ± 0.0 │ 100 │ ⋯
│ parameters.PhaseViscosities │ 0.003 ± 0.002 │ 200 │ ⋯
│ state0.Pressure │ 1.0e8 ± 0.0 │ 100 │ ⋯
│ state0.Saturations │ 0.5 ± 0.5 │ 200 │ ⋯
└─────────────────────────────┴───────────────────────────────────┴───────┴─────
2 columns omitted
No multipliers set.Plot the results
case_opt = opt.setup_function(prm_opt)
states_opt, = simulate(case_opt);
fig = Figure(size = (1200, 600))
ax = Axis(fig[1, 1], title = "Saturation")
lines!(ax, states_ref[end][:Saturations][1, :], label = "Reference")
lines!(ax, states[end][:Saturations][1, :], label = "Initial guess")
lines!(ax, states_tuned[end][:Saturations][1, :], label = "Tuned (Optim)")
lines!(ax, states_opt[end][:Saturations][1, :], label = "Tuned (reservoir_dict_optimization)")
axislegend(ax)
ax = Axis(fig[1, 2], title = "Pressure")
lines!(ax, states_ref[end][:Pressure], label = "Reference")
lines!(ax, states[end][:Pressure], label = "Initial guess")
lines!(ax, states_tuned[end][:Pressure], label = "Tuned (Optim)")
lines!(ax, states_opt[end][:Pressure], label = "Tuned (reservoir_dict_optimization)")
axislegend(ax)
fig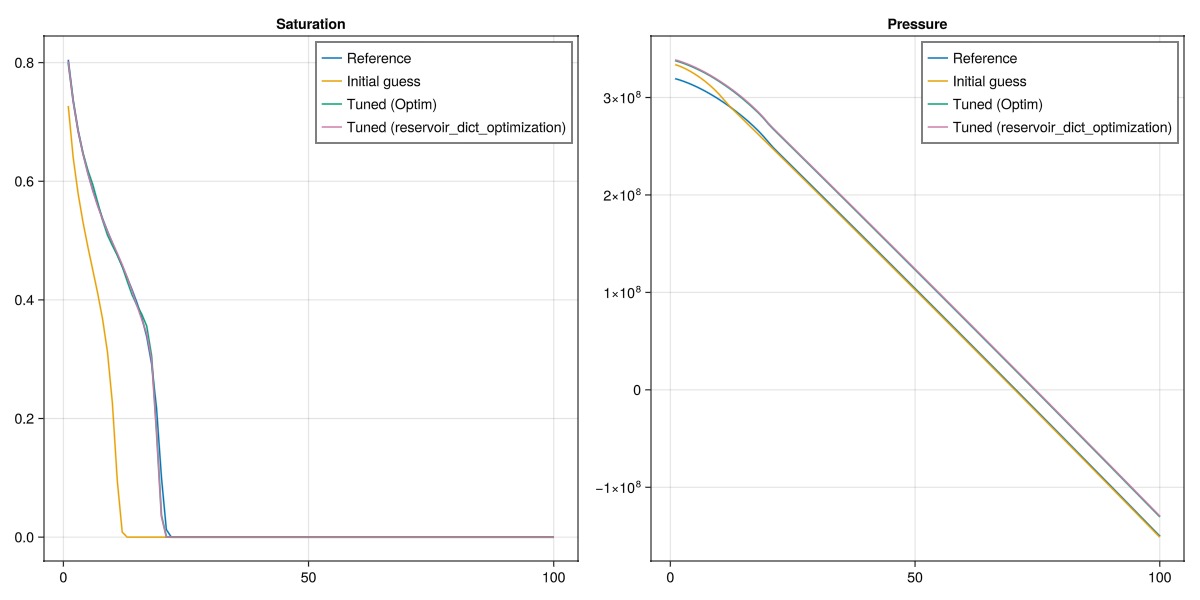
Plot the resulting porosities
Note that the porosity is only changed in the regions where the front has passed. As the objective function measures the difference in saturation, the objective function is only sensitive to the swept region where the saturation has changed.
fig = Figure()
ax = Axis(fig[1, 1], title = "Porosity")
scatter!(ax, prm_opt[:model][:porosity], label = "Optimized porosity")
lines!(ax, states[end][:Saturations][1, :], label = "Final saturation front")
fig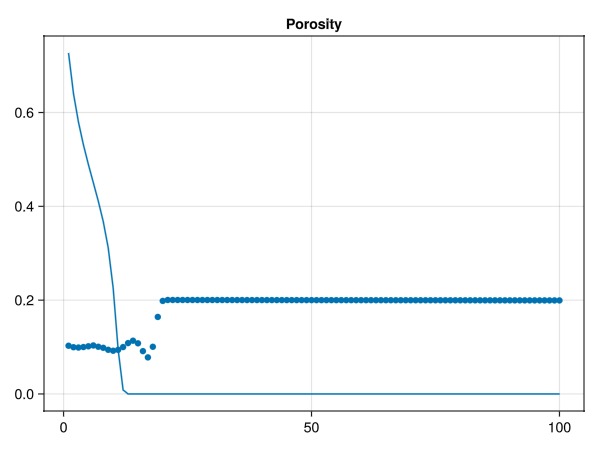
Optimize a single porosity parameter instead
If we introduce the prior assumption that the porosity is constant, we can optimize a single porosity parameter instead of the full porosity field. This is done by writing a setup function that takes a dictionary with the porosity and permeability as input parameters.
function setup_bl(d::AbstractDict, step_info = missing)
return setup_bl(poro = d[:poro], perm = d[:perm])
end
prm_1poro = Dict(:poro => 0.2, :perm => 0.1*si_unit(:darcy))
opt_1poro = setup_reservoir_dict_optimization(prm_1poro, setup_bl)
free_optimization_parameter!(opt_1poro, :poro, rel_min = 0.1, rel_max = 10.0)
prm_opt_1poro = optimize_reservoir(opt_1poro, saturation_mismatch);
opt_1poroDictParameters with 2 parameters (1 active), and 0 multipliers:
Active optimization parameters
┌──────┬───────────────┬───────┬──────┬─────┬─────────────────┬────────┐
│ Name │ Initial value │ Count │ Min │ Max │ Optimized value │ Change │
├──────┼───────────────┼───────┼──────┼─────┼─────────────────┼────────┤
│ poro │ 0.2 │ 1 │ 0.02 │ 2.0 │ 0.1 │ -50.0% │
└──────┴───────────────┴───────┴──────┴─────┴─────────────────┴────────┘
Inactive optimization parameters
┌──────┬───────────────┬───────┬─────┬─────┐
│ Name │ Initial value │ Count │ Min │ Max │
├──────┼───────────────┼───────┼─────┼─────┤
│ perm │ 9.87e-14 │ 1 │ - │ - │
└──────┴───────────────┴───────┴─────┴─────┘
No multipliers set.Plot the results for the single porosity parameter optimization
We observe that we now have recovered the single porosity parameter!
fig = Figure()
ax = Axis(fig[1, 1], title = "Porosity")
scatter!(ax, prm_opt[:model][:porosity], label = "Optimized porosity (all cells)")
scatter!(ax, fill(prm_opt_1poro[:poro], 100), label = "Optimized porosity (single parameter)")
lines!(ax, states[end][:Saturations][1, :], label = "Final saturation front")
axislegend()
fig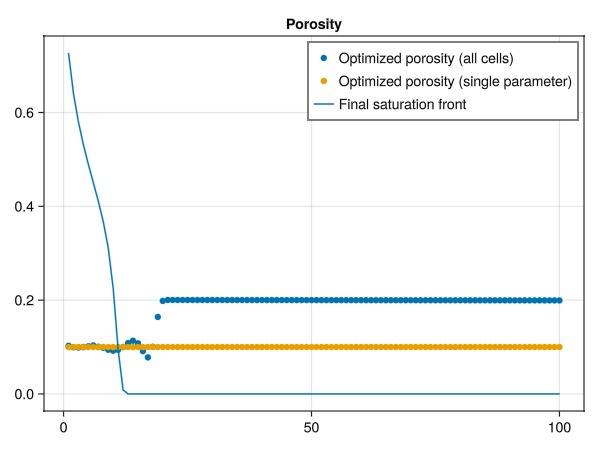
Example on GitHub
If you would like to run this example yourself, it can be downloaded from the JutulDarcy.jl GitHub repository as a script
This example took 102.199293452 seconds to complete.This page was generated using Literate.jl.